最新发布第4页
排序

Score-based模型图像生成的底层原理
一、问题定义 所谓图像生成实际上是拟合一个概率密度函数,经过解码器去生成图片。 假设我们有一个概率密度函数$P(x)$,其中$x$是一个图像,且$x\in R^d, 例如d=64\times64\times3$ 。现在,我...
深入解析:Gson与JSON的异同
深入解析:Gson与JSON的异同 引言 在现代软件开发中,数据交换格式扮演着至关重要的角色。JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式,因其简洁和易于阅读的特性而被广泛...

利用拓扑排序计算工程完成的最短时间
题目描述 有一项大的工程,工程中有许多前后依赖的子任务,每个子任务都规划了完成需要的天数,假设给出用字母表示的事件结点,整个工程的开始事件用A表示,工程结束事件用Z表示,用事件结点有...
Deep Learning Note 35 读取机器翻译数据集
import os import torch from d2l import torch as d2l d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip', '94646ad1522d915e7b0f9296181140edcf86a4f5'...
Java基础
Java基础合集 1 数据类型与输入输出 1.1 内置数据类型 类型 字节数 举例 byte 1 123 short 2 12345 int 4 123456789 long 8 1234567891011L float 4 1.2F double 8 1.2, 1.2D boolean 1 true, f...
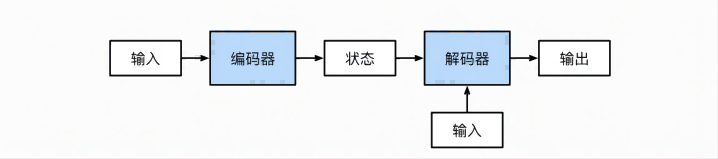
Deep Learning Note 36 Encoder-Decoder架构
架构示意图: Code 这里只有几个抽象类,只是给出了架构,具体需要自己实现 from torch import nn class Encoder(nn.Module): """基本编码器接口""" def __init_...
明星图像爬虫
import requests import time import random from urllib.request import urlretrieve import os class ImagesDownLoader(object): def __init__(self,name): self.headers = { 'User-Agen...
Deep Learning Note 34 LSTM的简洁实现
import torch from torch import nn from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) vocab_size, num_...
Deep Learning Note 38 Seq2Seq with Attention
import torch import torch.nn as nn from d2l import torch as d2l class AttentionDecoder(d2l.Decoder): """带有注意力机制的解码器基本接口""" def __init__...

为什么在VAE中,损失函数往往是最大化ELBO
因为 $$ KL = -ELBO + p_\theta(z|x_i) $$ 则有 $$ KL + ELBO = p_\theta(z|x_i) $$ 其中$p_\theta(z|x_i)$为一个常量 因此最大化ELBO实际上就是最小化$KL$散度