
深度学习 第2页
学习算法的一些记录~
排序

Deep Learning Note 32 门控循环单元
门控循环单元实际上是增加了对短期依赖关系和长期依赖关系的权重选择,使得序列预测更可靠 重置门有助于捕获序列中的短期依赖关系 更新门有助于捕获序列中的长期依赖关系 import torch from tor...
具有ID信息的文本图像对数据集制作
1. 图像下载(Image Downloading): 首先,列出了一个名人名单,这些名单可以从VoxCeleb和VGGFace等公开的名人面部数据集中获取。 根据名单,使用搜索引擎爬取数据,大约为每个名字下载100张图...

Transformer详解
Transformer 模型详解 1. Transformer 概览 2017 年,Google 在论文 Attention is All You Need 中提出了 Transformer 模型。Transformer 使用了 Self-Attention(自注意力) 机制,取代了在 NL...
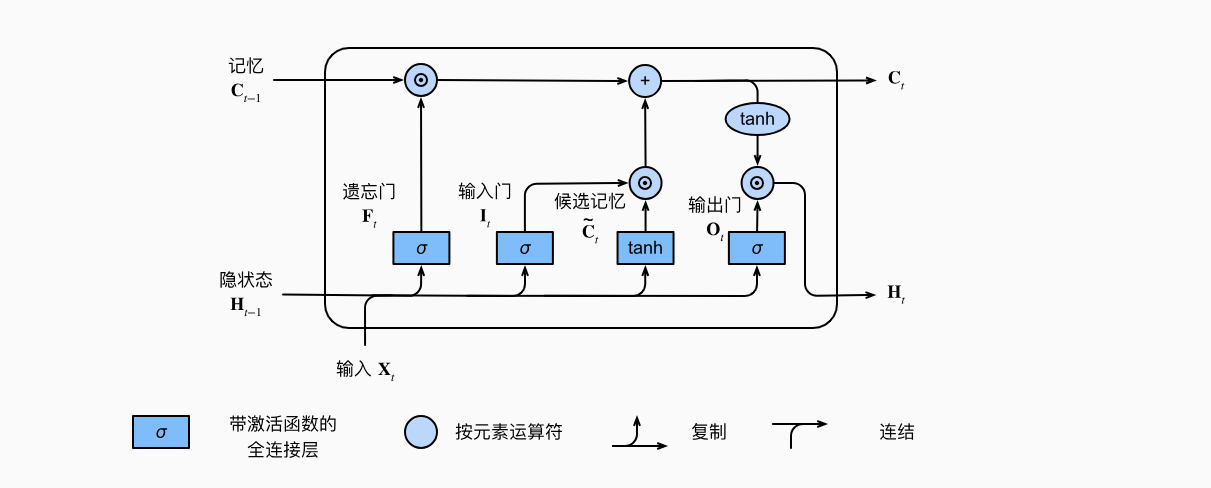
Deep Learning Note 33 LSTM的从零开始实现
李宏毅老师的图: import torch from torch import nn from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) ...
LSTM时序预测
# 引入依赖库 import pandas as pd import torch import matplotlib.pyplot as plt from sklearn import preprocessing from models import * from utils import * from sklearn.metrics import...
Deep Learning Note 35 读取机器翻译数据集
import os import torch from d2l import torch as d2l d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip', '94646ad1522d915e7b0f9296181140edcf86a4f5'...
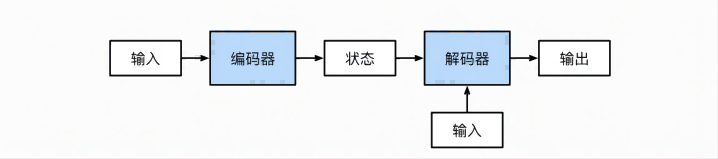
Deep Learning Note 36 Encoder-Decoder架构
架构示意图: Code 这里只有几个抽象类,只是给出了架构,具体需要自己实现 from torch import nn class Encoder(nn.Module): """基本编码器接口""" def __init_...
Deep Learning Note 38 Seq2Seq with Attention
import torch import torch.nn as nn from d2l import torch as d2l class AttentionDecoder(d2l.Decoder): """带有注意力机制的解码器基本接口""" def __init__...
Deep Learning Note 34 LSTM的简洁实现
import torch from torch import nn from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) vocab_size, num_...

为什么在VAE中,损失函数往往是最大化ELBO
因为 $$ KL = -ELBO + p_\theta(z|x_i) $$ 则有 $$ KL + ELBO = p_\theta(z|x_i) $$ 其中$p_\theta(z|x_i)$为一个常量 因此最大化ELBO实际上就是最小化$KL$散度