

深度学习共25篇
学习算法的一些记录~
排序
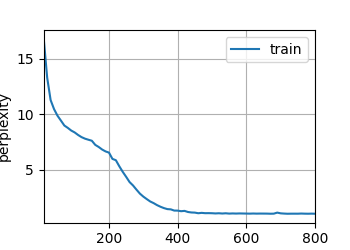
Deep Learning Note 30 循环神经网络(RNN)的从零开始实现
import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_tim...

论文笔记①High-Resolution Image Synthesis with Latent Diffusion Models
文献基本信息 文献名称: High-Resolution Image Synthesis with Latent Diffusion Models 期刊杂志: CVPR 2022 研究类型 类型: Research Article 文献基本内容 研究背景: 图像合成是计算机视觉...

Deep Learning Note 39 多头注意力
import math import torch from torch import nn from d2l import torch as d2l # 缩放点积注意力 class DotProductAttention(nn.Module): def __init__(self, dropout, **kwargs): super(DotPr...
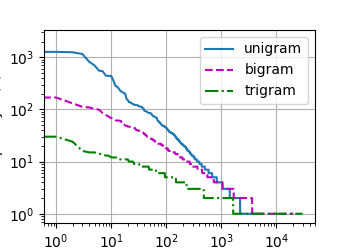
Deep Learning Note 29 自然语言统计与读取长序列数据
1、自然语言统计 import random import torch from d2l import torch as d2l tokens = d2l.tokenize(d2l.read_time_machine()) # 因为每个文本行不一定是一个句子或者一个段落,所以必须将所有...

论文笔记②Adding Conditional Control to Text-to-Image Diffusion Models
文献基本信息 文献名称: Adding Conditional Control to Text-to-Image Diffusion Models 期刊杂志: ICCV 2023 研究类型 类型: Research Article 文献基本内容 研究背景: 文本到图像的扩散模型...
Deep Learning Note 38 Seq2Seq with Attention
import torch import torch.nn as nn from d2l import torch as d2l class AttentionDecoder(d2l.Decoder): """带有注意力机制的解码器基本接口""" def __init__...

论文笔记③T2I-Adapter: Learning Adapters to Dig Out More Controllable Ability for Text-to-Image Diffusion Models
文献基本信息 文献名称: T2I-Adapter: Learning Adapters to Dig Out More Controllable Ability for Text-to-Image Diffusion Models 期刊杂志: AAAI 研究类型 类型: Research Article 文献基...
Deep Learning Note 37 注意力评分(Attention Score)
import math import torch from torch import nn from d2l import torch as d2l # 遮掩softmax操作 def masked_softmax(X, valid_lens): """通过最后一个轴上遮蔽元素来执行 sof...

论文笔记④DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
文献基本信息 文献名称: DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation 期刊杂志: CVPR 2023 研究类型 类型: Research Article 文献基本内容 研究背...
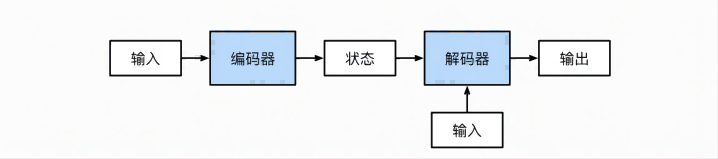
Deep Learning Note 36 Encoder-Decoder架构
架构示意图: Code 这里只有几个抽象类,只是给出了架构,具体需要自己实现 from torch import nn class Encoder(nn.Module): """基本编码器接口""" def __init_...