最新发布第3页
排序
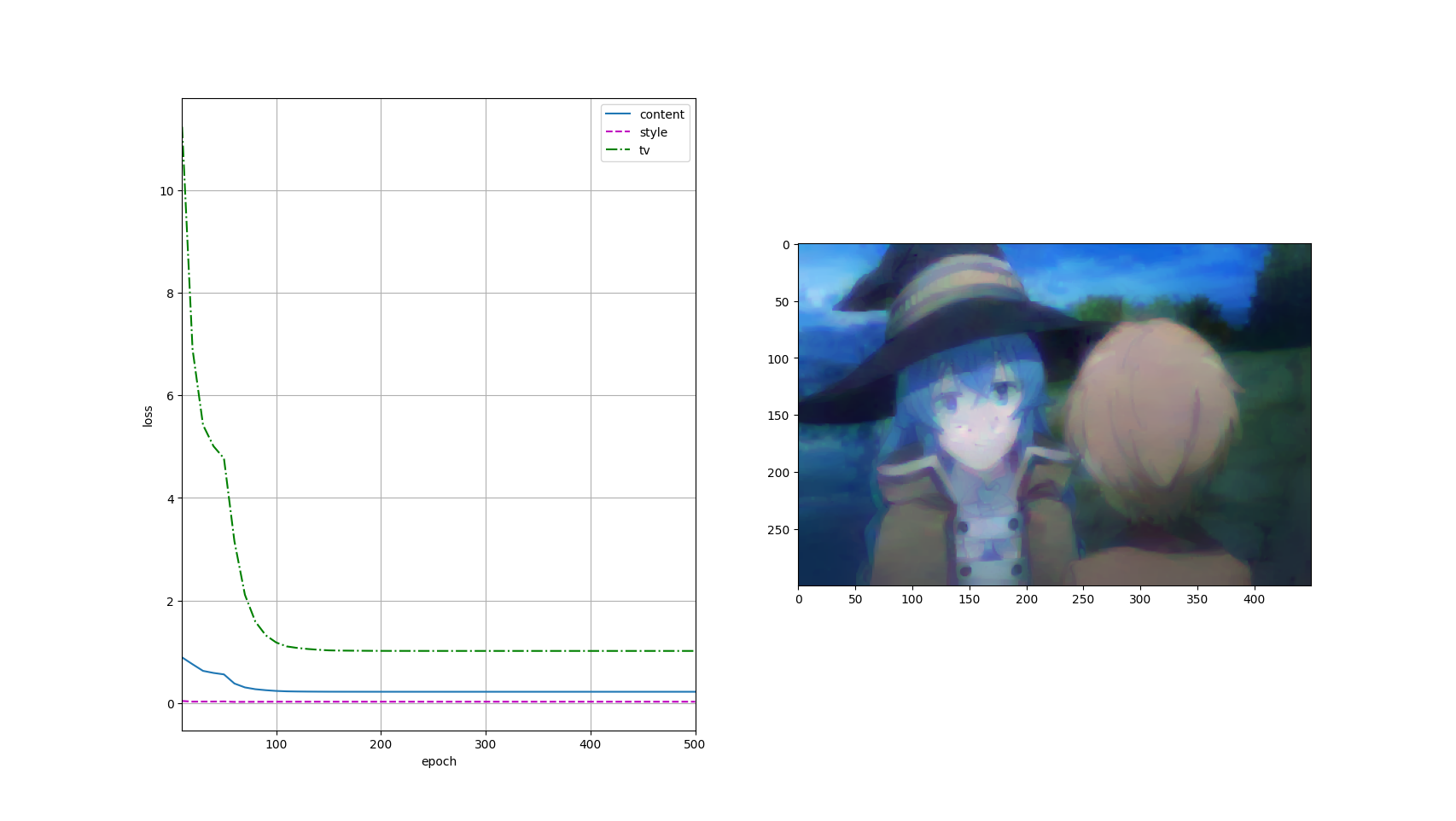
Deep Learning Note 41 风格迁移
import torch import torchvision from torchvision.models import vgg19, VGG19_Weights from torch import nn from d2l import torch as d2l d2l.set_figsize() content_img = d2l.Image.open...

前序遍历和后序遍历判断是否二叉树唯一
题目描述 假设二叉树中的所有键值都是不同的正整数。唯一的二元树可以通过给定的后序和顺序遍历序列,或前序和顺序遍历序列来确定。但是,如果仅给出后序和前序遍历序列,则相应的树可能不再...
🚀 省下$99!为 macOS 独立应用打造“零成本”自动更新方案
这篇文章介绍了独立开发者在macOS应用分发中遇到的痛点,即自动更新框架Sparkle需要支付费用才能使用,提出了一种利用GitHub Release Shell脚本实现0成本自动更新的“野路子”方案。文章详细说...
Deep Learning Note 39 多头注意力
import math import torch from torch import nn from d2l import torch as d2l # 缩放点积注意力 class DotProductAttention(nn.Module): def __init__(self, dropout, **kwargs): super(DotPr...
Deep Learning Note 38 Seq2Seq with Attention
import torch import torch.nn as nn from d2l import torch as d2l class AttentionDecoder(d2l.Decoder): """带有注意力机制的解码器基本接口""" def __init__...
Deep Learning Note 37 注意力评分(Attention Score)
import math import torch from torch import nn from d2l import torch as d2l # 遮掩softmax操作 def masked_softmax(X, valid_lens): """通过最后一个轴上遮蔽元素来执行 sof...
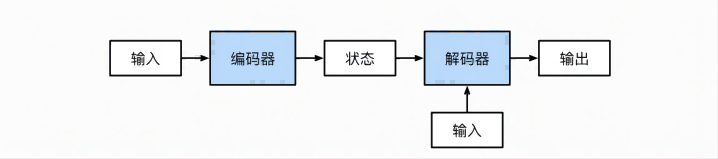
Deep Learning Note 36 Encoder-Decoder架构
架构示意图: Code 这里只有几个抽象类,只是给出了架构,具体需要自己实现 from torch import nn class Encoder(nn.Module): """基本编码器接口""" def __init_...
Deep Learning Note 35 读取机器翻译数据集
import os import torch from d2l import torch as d2l d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip', '94646ad1522d915e7b0f9296181140edcf86a4f5'...
Deep Learning Note 34 LSTM的简洁实现
import torch from torch import nn from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) vocab_size, num_...
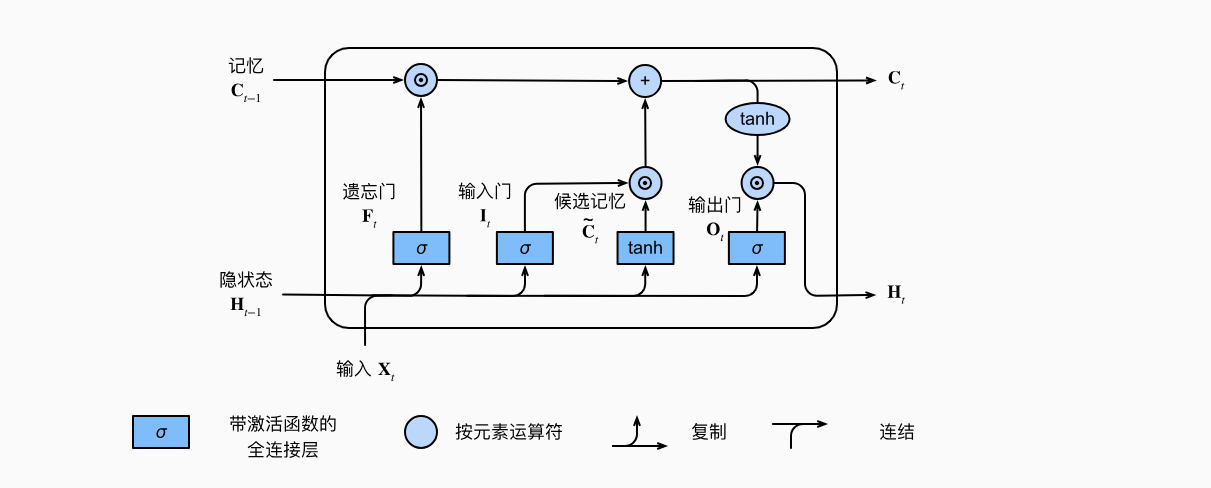
Deep Learning Note 33 LSTM的从零开始实现
李宏毅老师的图: import torch from torch import nn from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) ...