
深度学习 第3页
学习算法的一些记录~
排序

Deep Learning Note 39 多头注意力
import math import torch from torch import nn from d2l import torch as d2l # 缩放点积注意力 class DotProductAttention(nn.Module): def __init__(self, dropout, **kwargs): super(DotPr...
Deep Learning Note 40 Transformer
import math import torch import pandas as pd from torch import nn from d2l import torch as d2l # 基于位置的前馈网络(实际上就是一个两层的全连接) class PositionWiseFFN(nn.Module): de...
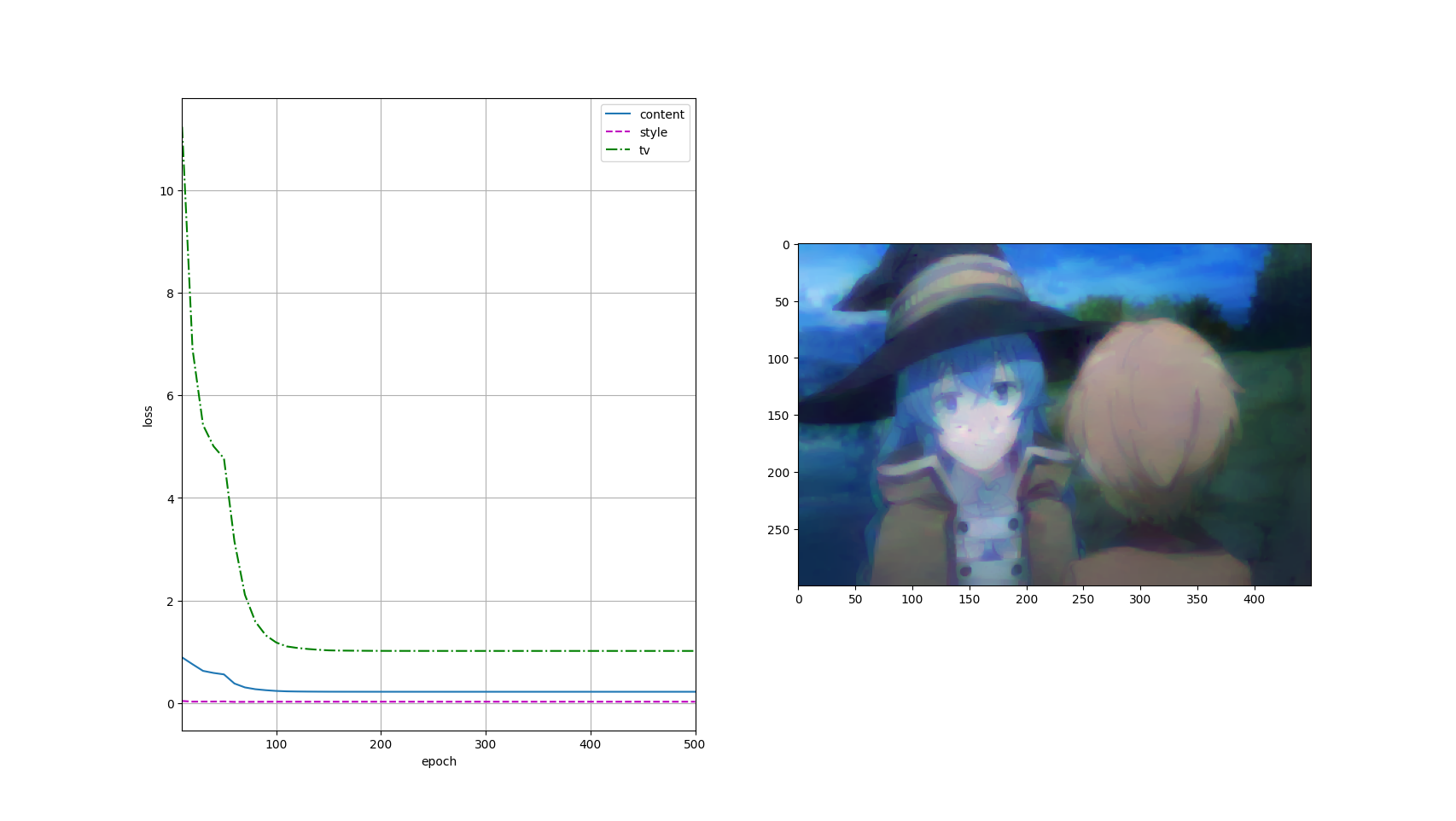
Deep Learning Note 41 风格迁移
import torch import torchvision from torchvision.models import vgg19, VGG19_Weights from torch import nn from d2l import torch as d2l d2l.set_figsize() content_img = d2l.Image.open...
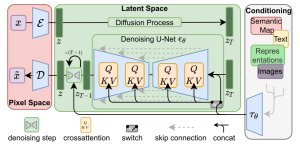
浅谈Diffusion ①理解 Latent Diffusion Model
Paper :High-Resolution Image Synthesis with Latent Diffusion Models 这篇文章是Stable Diffuion的开山之作了,接下来让我带大家看看这篇文章讲了些什么吧~ 1、研究背景 However, since thes...

为什么在VAE中,损失函数往往是最大化ELBO
因为 $$ KL = -ELBO + p_\theta(z|x_i) $$ 则有 $$ KL + ELBO = p_\theta(z|x_i) $$ 其中$p_\theta(z|x_i)$为一个常量 因此最大化ELBO实际上就是最小化$KL$散度