

Paper :High-Resolution Image Synthesis with Latent Diffusion Models
这篇文章是Stable Diffuion的开山之作了,接下来让我带大家看看这篇文章讲了些什么吧~
1、研究背景
However, since these models typically operate directly in pixel space, optimiza- tion of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evalu- ations.
对于传统的DM模型,在pixel space上去进行图像的加噪与去噪,这对模型的训练效率非常不利,我们是否有一个更加小的空间去用来加噪和去噪呢?想想之前学习的nlp领域的Transformer中的潜空间,我们是否可以构建类似的空间,然后在这个潜在空间中加噪去噪去达到扩散模型的效果呢?
因此,Latent Diffusion横空出世,通过在潜在表示空间(latent space)上进行diffusion过程的方法,大大减少了计算复杂度并达到了较好的效果。
2、模型优势
LDM模型不仅可以大大减少时间复杂度,而且可以生成更加细致的图像,并且在超高分辨率图片生成任务上表现的也很好!
不仅如此,论文还提出了cross-attention(交叉注意力)的方法来实现多模态的训练,使得条件图片生成任务成为可能!论文中提到的条件图片生产任务包括类别条件图片生成(class-condition),文生图(text to image),布局条件图片生成(layout to image)。这为如今AI绘画领域的宏大打下了坚实的基础。
3、模型原理
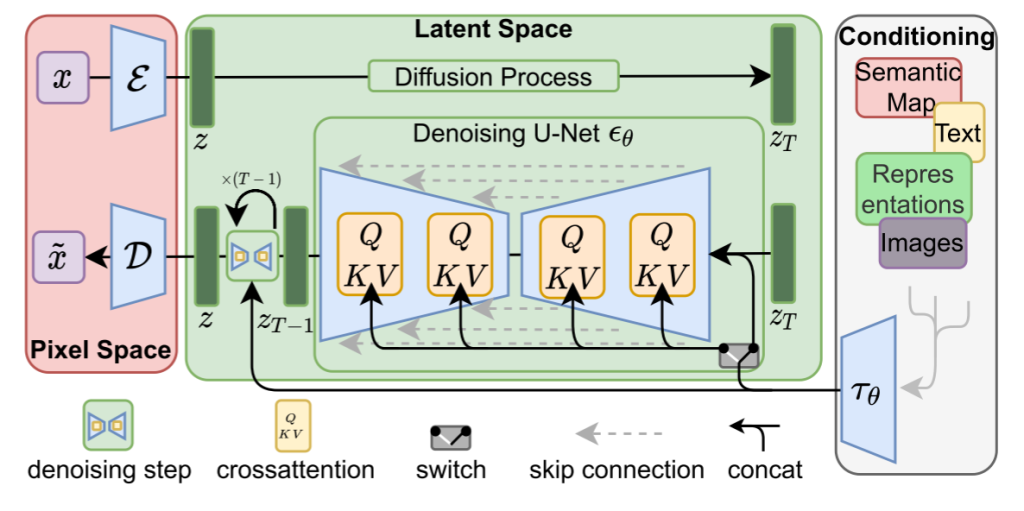
我们先来看看paper中给出的原理图
![图片[1]-浅谈Diffusion ①理解 Latent Diffusion Model-MuQYY的博客](https://s21.ax1x.com/2024/07/24/pkb9trn.png)
我们分为图片感知压缩、潜在扩散模型、条件机制三个方面来理解
3.1、图片感知压缩
图片感知压缩特点如下:
- 目的:给定一个图像$x$,编码器把$x$编码成潜空间的$z$,解码器从潜空间把$z$解码回$\tilde{x}$。
- 训练loss: KL正则和VQ正则。
3.2、潜在扩散模型
潜在扩散模型中,引入了预训练的感知压缩模型,它包含一个解码器和一个编码器,这样就可以在训练的时候利用编码器得到$z_t$,从而让模型在潜在空间中学习。
3.3 条件机制
条件机制本质在于通过交叉注意力机制增强底层的Unet主干,将DM转为更加灵活的条件图像生成器。
$$Attention(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt[]{d} } )\cdot V$$
4、训练与推理
4.1、训练
训练分为两个步骤:
首先训练得到一个VAE,即$x$到$z_t$的Encoder和还原$x'$的Decoder。
然后再训练中间的LDM扩散模型,学习噪声到$z_t$的生成过程,其中LDM架构是一个Unet
4.2、推理
推理分为无条件信息和有条件信息,如果无条件信息则通过高斯噪声采样,经过LDM模型得到潜空间图像$z_t$,然后经过Decoder还原到原图。
如果有条件,则条件信息通过条件处理的编码器得到的输出与初始高斯噪声进行耦合,再经过LDM得到潜空间图像$z_t$,经过Decoder还原到原图。
- 1本网站名称:MuQYY
- 2本站永久网址:www.muqyy.top
- 3本网站的文章部分内容可能来源于网络,仅供大家学习与参考,如有侵权,请联系站长 微信:bwj-1215 进行删除处理。
- 4本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
- 5本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
- 6本站资源大多存储在云盘,如发现链接失效,请联系我们我们会在第一时间更新。






暂无评论内容