

文献基本信息
- 文献名称: Imagic: Text-Based Real Image Editing with Diffusion Models
- 期刊杂志: CVPR 2023
研究类型
- 类型: Research Article
文献基本内容
- 研究背景: 大规模文本到图像模型展示了根据文本提示生成高质量和多样化图像的能力,但缺乏模仿给定参考集中主体外观并合成它们在不同上下文中的新表现的能力。
- 先前研究的局限性: 现有模型通常限于特定类型的编辑(例如,对象叠加、风格转换)或只能处理合成图像,且可能需要额外的输入(例如图像遮罩或多个视角的图像)。
- 研究目的: 提出一种新技术,通过微调预训练的文本到图像扩散模型,使其能够根据少量真实图像和文本提示进行复杂的图像编辑。
- 研究方法:
- 使用少量真实图像微调预训练模型。
- 引入自生类特定先验保留损失,利用模型中嵌入的语义先验。
- 是否具有创新性: 是,提出了一种新颖的方法,能够在不同场景中生成特定主体的图像,同时保留其关键视觉特征。
已解决的问题
- 研究的创新性: Imagic能够通过文本提示对真实图像进行复杂的语义编辑。
未解决的问题
- 论文中提到的局限性包括在某些情况下编辑可能不够显著,或者可能影响图像的外部细节,如缩放或相机角度。
对自己课题的意义
- Imagic为图像编辑领域提供了一种新颖的方法,允许用户通过文本提示对真实图像进行精细控制,这对于那些希望在不同上下文中生成特定主体图像的应用领域具有潜在价值。
可借鉴的内容
- 方法: 利用扩散模型进行图像编辑,以及通过文本嵌入进行语义操作的方法。
- 思路: 通过微调预训练模型来嵌入特定主体,以便在不同的文本提示下生成图像。
注意事项
- 可能出现错误的环节: 在尝试生成与训练数据分布显著不同的图像时,模型可能会产生不准确的结果。
详细方法部分
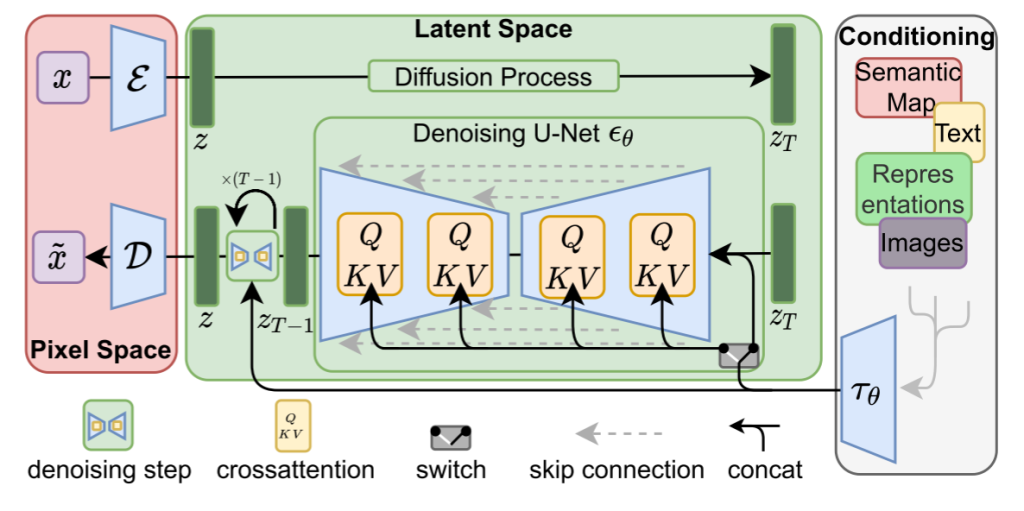
- 文本嵌入优化: 通过优化过程找到与输入图像最匹配的文本嵌入。
- 模型微调: 微调模型以更好地重建输入图像,同时保留其细节。
- 插值与生成: 在优化的文本嵌入和目标文本嵌入之间进行线性插值,生成最终的编辑结果。
优化文本嵌入
1. 目标文本编码
首先,将目标文本通过一个文本编码器转换为初始的文本嵌入 $ e_{\text{tgt}} $。这个文本编码器通常是基于Transformer的模型,能够将文本转换为一个连续的向量表示。
2. 初始化扩散模型
使用一个预训练的扩散模型,该模型能够根据文本嵌入和噪声生成图像。扩散模型 $ f_{\theta} $ 的参数 $ \theta $ 在此阶段是固定的。
3. 优化目标文本嵌入
通过以下目标函数来优化目标文本嵌入:
$$
L_{\text{opt}} = \mathbb{E}_{t, \epsilon} \left[ \left\| \epsilon - f_{\theta}(x_t, t, e_{\text{tgt}}) \right\|_2^2 \right]
$$
这里,$ x_t $ 是输入图像 $ x $ 的噪声版本,$ t $ 是均匀分布的时间步长,$ \epsilon $ 是从高斯分布 $ \mathcal{N}(0, I) $ 中采样的噪声。
4. 迭代优化
使用梯度下降算法(例如Adam优化器)来迭代更新文本嵌入 $ e_{\text{tgt}} $,以最小化上述损失函数。这个过程的目标是找到一个文本嵌入 $ e_{\text{opt}} $,它能够在扩散模型的指导下生成与输入图像尽可能相似的图像。
5. 保持文本嵌入接近原始
优化过程通常只运行有限的步数,以确保优化后的文本嵌入 ( $e_{\text{opt}}$ ) 仍然接近初始的目标文本嵌入,这有助于在嵌入空间中进行有意义的线性插值。
6. 利用优化的文本嵌入
一旦找到优化的文本嵌入 $ e_{\text{opt}} $,就可以使用它来指导扩散模型生成新的图像,这些图像不仅与输入图像相似,而且还能够反映目标文本描述的语义内容。
通过这个过程,Imagic 方法能够有效地将文本描述与图像内容相结合,实现对真实图像的语义编辑。
### 方法图

- 1本网站名称:MuQYY
- 2本站永久网址:www.muqyy.top
- 3本网站的文章部分内容可能来源于网络,仅供大家学习与参考,如有侵权,请联系站长 微信:bwj-1215 进行删除处理。
- 4本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
- 5本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
- 6本站资源大多存储在云盘,如发现链接失效,请联系我们我们会在第一时间更新。





暂无评论内容