
深度学习 第2页
学习算法的一些记录~
排序

LSTM时序预测
# 引入依赖库 import pandas as pd import torch import matplotlib.pyplot as plt from sklearn import preprocessing from models import * from utils import * from sklearn.metrics import...
Flow Matching的数学原理
这篇文章介绍了Flow Matching作为一种生成模型训练方法,将其视为扩散模型的更通用形式。其核心思想是将数据视为在流场中运动的粒子,通过学习一个与时间相关的向量场来引导粒子从先验分布移动...
Deep Learning Note 32 门控循环单元
门控循环单元实际上是增加了对短期依赖关系和长期依赖关系的权重选择,使得序列预测更可靠 重置门有助于捕获序列中的短期依赖关系 更新门有助于捕获序列中的长期依赖关系 import torch from tor...
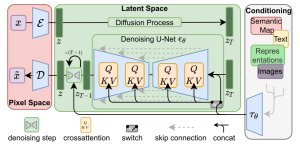
浅谈Diffusion ①理解 Latent Diffusion Model
Paper :High-Resolution Image Synthesis with Latent Diffusion Models 这篇文章是Stable Diffuion的开山之作了,接下来让我带大家看看这篇文章讲了些什么吧~ 1、研究背景 However, since thes...
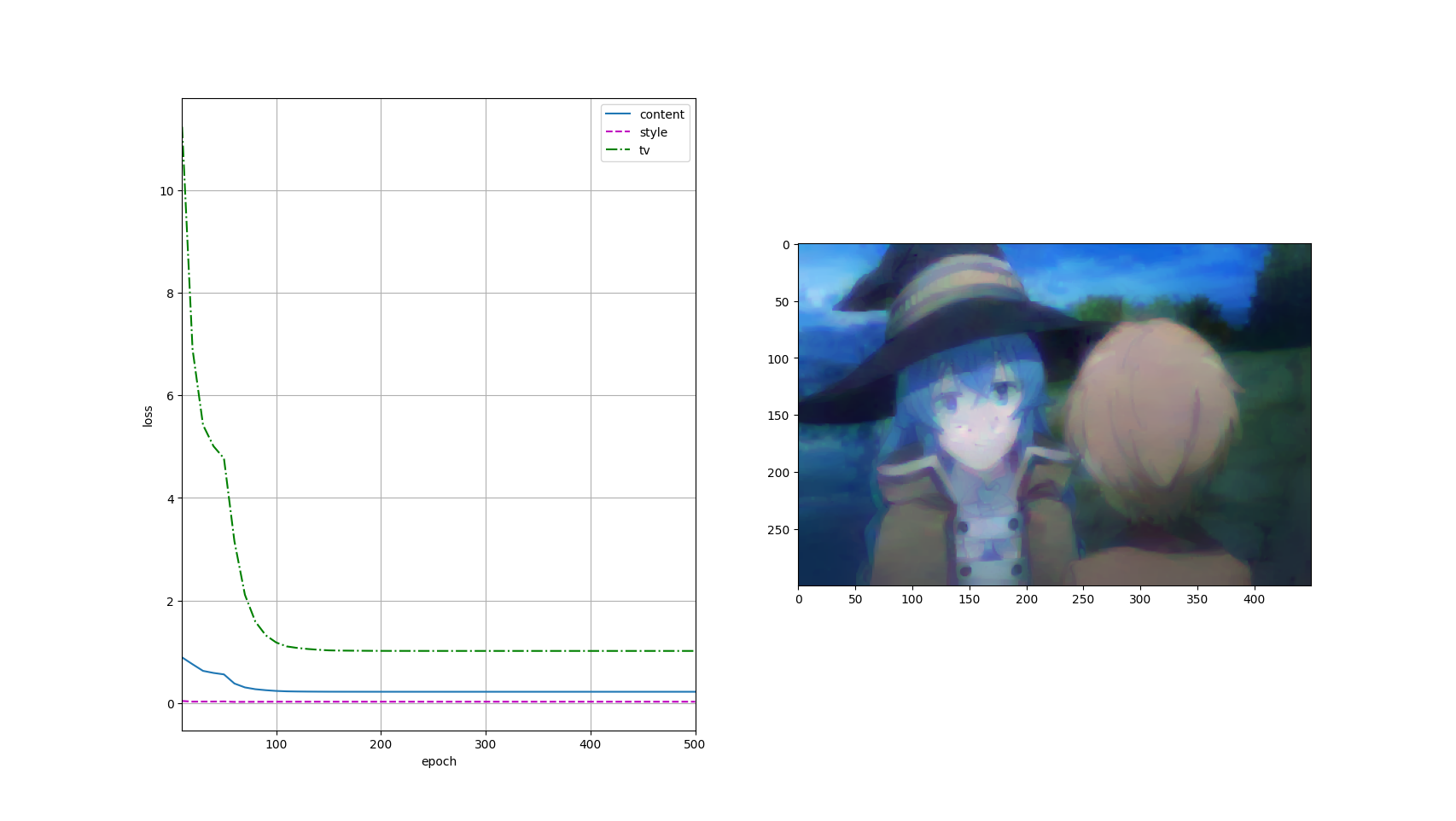
Deep Learning Note 41 风格迁移
import torch import torchvision from torchvision.models import vgg19, VGG19_Weights from torch import nn from d2l import torch as d2l d2l.set_figsize() content_img = d2l.Image.open...
Deep Learning Note 31 RNN的简洁实现
import torch from torch import nn from d2l import torch as d2l from torch.nn import functional as F batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(ba...

为什么在VAE中,损失函数往往是最大化ELBO
因为 $$ KL = -ELBO + p_\theta(z|x_i) $$ 则有 $$ KL + ELBO = p_\theta(z|x_i) $$ 其中$p_\theta(z|x_i)$为一个常量 因此最大化ELBO实际上就是最小化$KL$散度
Deep Learning Note 40 Transformer
import math import torch import pandas as pd from torch import nn from d2l import torch as d2l # 基于位置的前馈网络(实际上就是一个两层的全连接) class PositionWiseFFN(nn.Module): de...
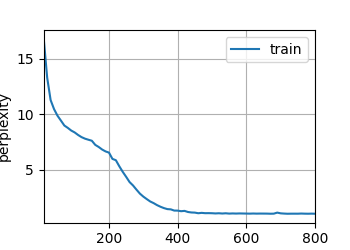
Deep Learning Note 30 循环神经网络(RNN)的从零开始实现
import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_tim...

论文笔记①High-Resolution Image Synthesis with Latent Diffusion Models
文献基本信息 文献名称: High-Resolution Image Synthesis with Latent Diffusion Models 期刊杂志: CVPR 2022 研究类型 类型: Research Article 文献基本内容 研究背景: 图像合成是计算机视觉...