

1、自然语言统计
import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或者一个段落,所以必须将所有文本行拼接成一个单词列表
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
print(vocab.token_freqs[: 10])
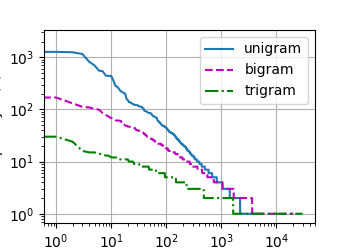
# 画一下词频图
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)', xscale='log', yscale='log')
# d2l.plt.show()
# 二元语法
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
print(bigram_vocab.token_freqs[: 10])
# 三元语法
trigram_tokens = [triple for triple in zip(
corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
print(trigram_vocab.token_freqs[: 10])
# 作图,观察词频分布
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
d2l.plt.show()
2、读取长序列数据
# 读取长序列数据
# 1.随机抽样
def seq_data_iter_random(corpus, batch_size, num_steps):
"""
使用随机抽样生成一个小批量子序列。
参数:
- corpus: 输入序列的列表。
- batch_size: 每个批次的大小。
- num_steps: 每个子序列的长度。
返回:
- 产生器,每次产生一个包含batch_size个子序列对(X, Y)的元组,其中X是输入序列,Y是对应的下一个字符。
"""
# 对序列进行随机裁剪,确保至少有num_steps个元素
corpus = corpus[random.randint(0, num_steps - 1):]
# 计算可生成的子序列数量
num_subseqs = (len(corpus) - 1) // num_steps
# 准备子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 对起始索引进行随机排序,以实现随机的子序列采样
random.shuffle(initial_indices)
def data(pos):
# 根据给定位置提取num_steps长度的子序列
return corpus[pos: pos + num_steps]
# 计算总共可以生成的批次数量
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 获取当前批次的起始索引列表
initial_indices_per_batch = initial_indices[i: i + batch_size]
# 根据起始索引生成输入序列X和目标序列Y
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
# 生成并返回当前批次的输入和目标序列
yield torch.tensor(X), torch.tensor(Y)
# 2、顺序分区
def seq_data_iter_sequential(corpus, batch_size, num_steps):
"""
使用顺序分区生成一个小批量子序列。
"""
# 从随机偏移量开始拆分系列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // num_steps) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
class SeqDataLoader:
"""
一个用于加载序列数据的迭代器。
"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_time_machine(batch_size, num_steps, use_random_iter=False, max_tokens=10000):
"""
加载时间机器数据集。
"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab© 版权声明
版权声明
- 1本网站名称:MuQYY
- 2本站永久网址:www.muqyy.top
- 3本网站的文章部分内容可能来源于网络,仅供大家学习与参考,如有侵权,请联系站长 微信:bwj-1215 进行删除处理。
- 4本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
- 5本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
- 6本站资源大多存储在云盘,如发现链接失效,请联系我们我们会在第一时间更新。
THE END






暂无评论内容