

文献基本信息
- 文献名称: DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- 期刊杂志: CVPR 2023
研究类型
- 类型: Research Article
文献基本内容
- 研究背景: 大型文本到图像模型虽然能够根据文本提示生成高质量和多样化的图像,但缺乏模仿给定参考集中主体外观并合成它们在不同上下文中的新表现的能力。
- 先前研究的局限性: 现有模型无法准确重建给定主体的外观,只能创建图像内容的变化。
- 研究目的: 提出一种新技术,通过微调预训练的文本到图像模型,使其能够将特定主体与独特的标识符绑定,从而在不同场景中生成该主体的新颖、逼真图像。
- 研究方法:
- 使用少量(通常3-5张)主体图像进行微调。
- 引入了一种新的自生类特定先验保留损失(class-specific prior preservation loss),利用模型中嵌入的语义先验,鼓励生成与主体类别相同的多样化实例。
- 是否具有创新性: 是,提出了一种新的个性化文本到图像扩散模型的方法,允许在不同场景中生成特定主体的图像,同时保留其关键特征。
- 研究思路(技术路线):
- 微调预训练的文本到图像扩散模型,使用包含独特标识符和主体类别名称的文本提示。
- 应用自生类特定先验保留损失,防止语言漂移(language drift),并鼓励模型生成多样化的主体实例。
- 对多种文本引导的图像生成应用进行评估,包括主体重新上下文化、视角引导合成和艺术渲染。
- 研究结果: DreamBooth技术能够成功地在多种场景中生成特定主体的图像,同时保留其关键视觉特征,并在不同的文本提示下展现出高保真度。
- 文献意义: 为特定主体的图像生成提供了一种新颖的方法,允许用户使用少量图像合成在不同上下文中的新颖表现,为图像编辑和合成开辟了新的可能性。
已解决的问题
- 研究的创新性: 通过微调文本到图像扩散模型,实现了对特定主体在不同上下文中的图像生成的控制。
未解决的问题
- 研究的局限性: 论文中提到了一些可能的失败模式,包括无法准确生成提示的上下文、上下文和主体外观的纠缠,以及模型可能过度拟合训练集中的图像。
对自己课题的意义
- DreamBooth技术为需要在不同上下文中生成特定主体图像的应用提供了一种新的方法,例如虚拟试衣、角色定制等。
可借鉴的内容
- 方法: 使用少量图像进行微调,以及引入自生类特定先验保留损失的方法。
- 思路: 将特定主体嵌入到模型的输出域中,以便使用文本提示进行控制生成。
注意事项
- 可能出现错误的环节: 在生成与训练集不同的新上下文或主体变化时,模型可能无法准确生成预期的图像。
详细方法部分
- 微调技术: 利用少量图像和特定文本提示微调预训练模型,使其学习将特定主体与唯一标识符绑定。
- 类特定先验保留损失: 通过监督模型使用自身生成的样本来保留类别先验,同时生成多样化的主体实例。
- 应用: 展示了在不同上下文中重新上下文化主体、修改主体属性、艺术渲染和视角修改等应用。
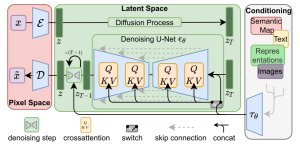
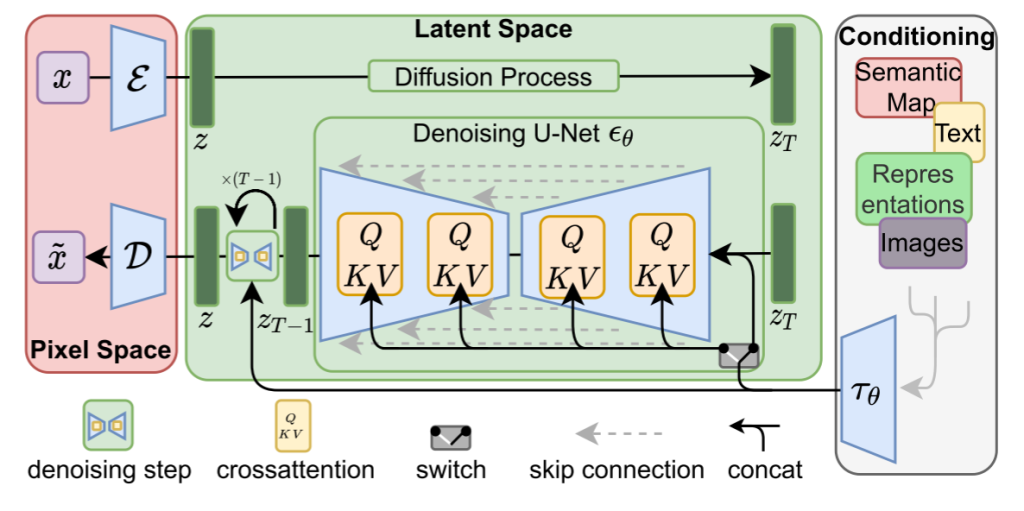
方法图

© 版权声明
版权声明
- 1本网站名称:MuQYY
- 2本站永久网址:www.muqyy.top
- 3本网站的文章部分内容可能来源于网络,仅供大家学习与参考,如有侵权,请联系站长 微信:bwj-1215 进行删除处理。
- 4本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
- 5本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
- 6本站资源大多存储在云盘,如发现链接失效,请联系我们我们会在第一时间更新。
THE END





暂无评论内容