

## 点云降采样核心技术概览:从随机采样到深度学习
在处理三维点云数据时,降采样(Downsampling)是一个至关重要且无法回避的预处理步骤。原始点云数据量庞大,动辄数百万甚至上千万点,这给后续的存储、计算和分析(如配准、特征提取、三维重建等)带来了巨大的挑战。降采样旨在保证点云原有特征和形状不失真的前提下,大幅减少数据量,从而提升算法效率。
本文将系统梳理几种主流的点云降采样方法,从最基础的随机采样,到基于几何特征的方法,再到前沿的深度学习方案。
### 1. 随机采样 (Random Sample)
随机采样是最简单、最直接的降采样方法。顾名思义,它从原始点云中随机选取指定数量的点作为采样后的结果。
- **核心思想**:无差别地、随机地选择点。
- **优点**:算法实现简单,时间复杂度极低,处理速度最快。
- **缺点**:由于其随机性,它无法保证采样点的均匀分布,也几乎不保留点云的局部结构和关键特征。采样结果的质量较低,通常只适用于对点云进行粗略的可视化预览,而不适用于需要精确分析的任务(如配准或精细的特征提取)。
### 2. 均匀采样 (Uniform Sample / Voxel Grid Downsampling)
均匀采样是一种更为常用且效果优于随机采样的方法。它通过将点云空间划分为一个个均匀的“体素”(Voxel,即三维小方格),并在每个体素内仅保留一个代表点来实现降采样,从而保证了采样后点云的均匀分布。
- **核心思想**:在空间上划分网格,每个网格只保留一个点。
- **代表点选择策略**:
1. **体素中心**:直接使用体素的几何中心点(此方法不常用,因为它会生成不存在于原始点云中的新点)。
2. **最近邻点**:选择体素内距离体素中心最近的原始点。这是最常用、效果也较好的策略。
3. **随机点**:在体素内随机选择一个原始点。
4. **质心/平均点**:计算体素内所有点的质心(平均坐标)。CloudCompare中的`Octree Sample`就采用了类似的思想。需要注意的是,对于包含不同类别物体的点云(如“人”和“牛”的点混在一个体素),取平均值可能会产生无意义的点。
- **基本流程**:
1. 确定一个能完全包围所有点云的“巨大”边界框(Bounding Box)。
2. 设定体素的大小(Voxel Size),这是控制采样密度的关键参数。
3. 根据体素大小,计算XYZ三个方向上划分的网格数量。
4. 遍历所有原始点,确定每个点所属的体素索引。
5. 在每个非空体素中,根据所选策略(如选择离中心最近的点)保留一个点。
- **性能优化**:对于海量点云,遍历和管理所有体素的开销巨大。此时可以引入哈希表(Hash Table)进行优化。
- **哈希优化流程**:将每个体素的索引(例如,通过其三维坐标计算出的唯一ID)作为哈希键(Key)。遍历原始点云,将每个点映射到其对应体素的哈希桶(Bucket)中。由于多个点会映射到同一个哈希键,我们只需在每个桶中保留一个点即可。这种方式避免了对巨大体素空间的直接索引和排序,大大提升了处理效率。
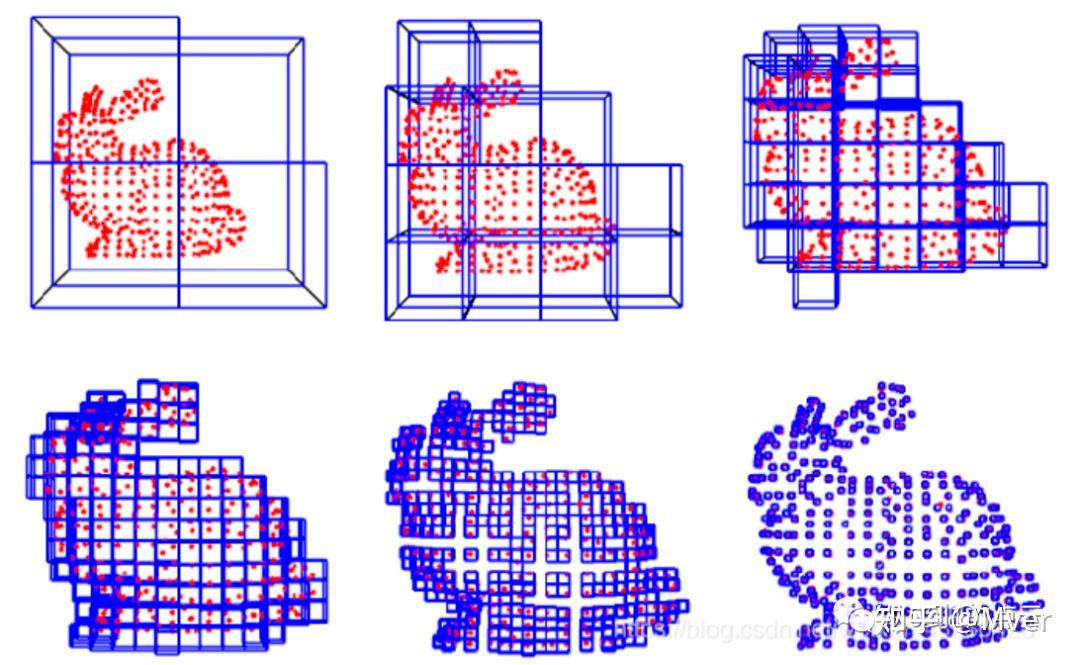
### 3. 最远点采样 (Farthest Point Sample, FPS)
最远点采样(FPS)是一种追求采样点最大化覆盖原始点云空间的算法。它生成的采样点集在分布上比均匀采样更优,尤其能很好地覆盖到点云的边界和突出部分。
- **核心思想**:从一个初始点开始,迭代地选择距离当前已选点集最远的点加入。
- **流程**:
1. 从原始点云中随机选择一个点作为起始点,加入采样点集。
2. 对于点云中的每一个剩余点,计算它到采样点集中所有点的最短距离。
3. 选择该最短距离最大的那个点(即离当前采样点集“最远”的点),将其加入采样点集。
4. 重复步骤2和3,直到采样点的数量达到预设目标。
- **优点**:采样点分布均匀,覆盖性好,能够更好地保留点云的整体骨架和几何外形。著名的PointNet++网络就利用FPS对其输入数据进行分层和分组。
- **缺点**:计算量巨大,算法复杂度高(约为O(N\*M),N为原始点数,M为采样点数),在处理大规模点云时速度非常慢。
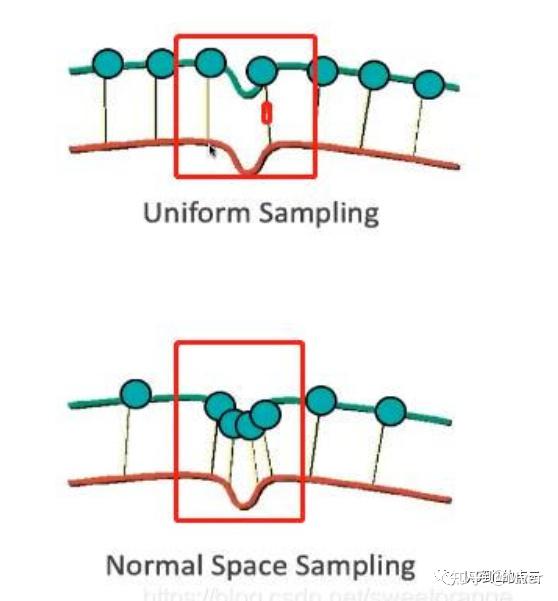
### 4. 法向量空间采样 (Normal Space Sampling)
这种方法的目标是保留点云的几何细节,特别是那些曲率变化剧烈的区域。它通过分析点的法向量(Normal Vector)来实现,确保采样后点的法向量在空间中尽可能均匀分布。
- **核心思想**:使得采样后点集的法向量方向分布尽可能均匀,从而优先保留几何特征丰富的点。
- **效果**:如果一个区域是平坦的,那么该区域所有点的法向量方向都非常相似,NSS会在这里采很少的点。如果一个区域是边角或高曲率区域,点的法向量方向变化剧烈,NSS则会在这里保留更多的点。
- **优势**:相比均匀采样,NSS在保留点云细节方面表现出色,尤其适用于需要进行精细特征匹配或分析的场景。
### 5. 基于去噪的采样方法
去噪(Denoising)和降采样虽然目标不同,但在操作本质上有共通之处——都是从原始点集中移除一部分点。因此,一些去噪算法也可以被视为一种特殊的降采样策略,其主要目标是剔除离群点(Outliers)。
- **Radius Outlier Removal (ROR)**:遍历所有点,如果某个点在其指定半径(R)范围内的邻近点数量少于一个阈值(K),则将其视为噪声点并移除。此方法的挑战在于半径R和阈值K的选择。
- **Statistical Outlier Removal (SOR)**:这是一种基于统计学的去噪方法。它首先计算每个点到其所有邻近点的平均距离。假设这些平均距离构成一个高斯分布,那么那些平均距离落在分布之外(通常是根据全局均值和标准差定义的范围之外)的点被定义为离群点并被剔除。
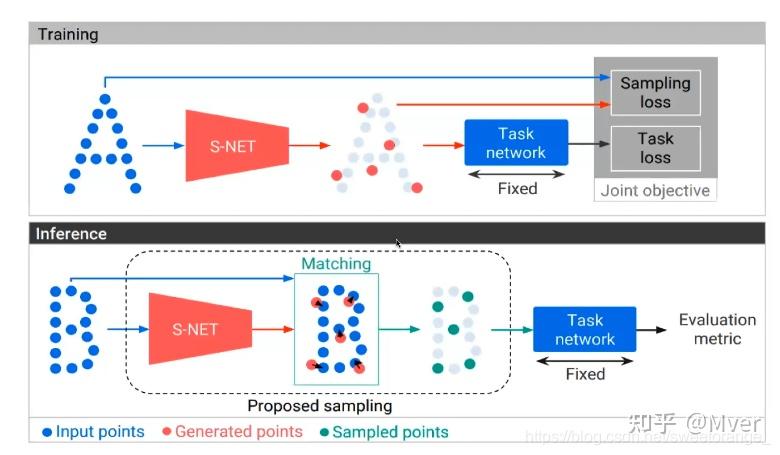
### 6. 深度学习驱动的降采样
随着深度学习在三维领域的兴起,基于神经网络的降采样方法也应运而生。这类方法不再仅仅依赖几何分析,而是通过学习来理解点云的语义信息,并进行更有目的性的采样。
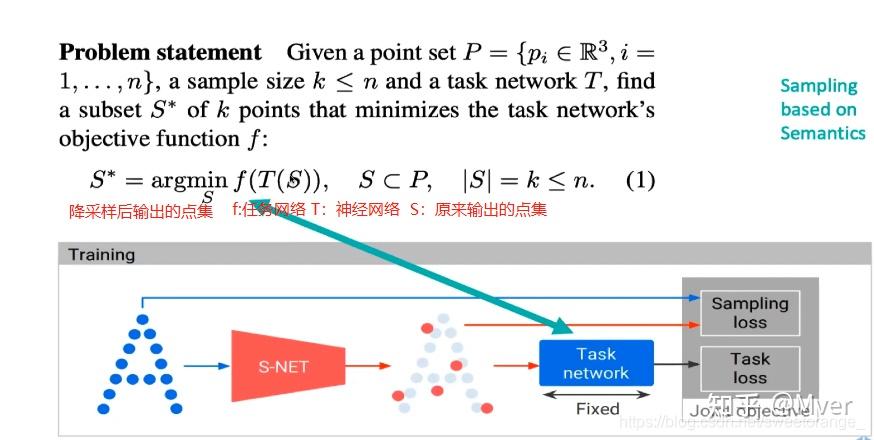
- **核心思想**:通过神经网络(如PointNet、DGCNN等)对点云进行分析,输出一个采样矩阵或直接生成采样后的点。网络可以被训练来保留对特定下游任务(如分类、分割)最重要的点。
- **优势**:通过端到端的学习,可以实现“任务驱动”的降采样。例如,为了进行物体分类,网络会学习保留那些最具区分度的特征点。实验证明,尤其是在采样点数较少的情况下,这种方法用于分类任务的准确率远高于传统几何采样方法。
- **应用**:一个典型的评估标准是**归一化重建误差 (Normalized Reconstructed Error)**,即衡量降采样后的点云在多大程度上可以重建出原始点云的几何形态。
### 7. 基于法向量聚类的降采样
这是一种结合了体素化和法向量分析的进阶方法。
- **流程**:
1. 对点云进行体素化。
2. 为每个体素内的点云估计一个平均法向量。
3. 对所有体素的法向量进行聚类分析。
4. 保留每个聚类中的代表性点,删除那些法向量相似的冗余点。
- **优势**:通过删除法向量相似的点,该方法能有效剔除平面等冗余区域的点,同时保留边、角等关键特征点。
### 结语
点云降采样技术种类繁多,没有一种方法是“万能”的。在实际应用中,我们需要根据具体的任务需求、点云特性以及对效率和精度的要求来权衡选择:
- **快速预览**:选择随机采样。
- **通用预处理**:均匀采样(Voxel Grid)是效率和效果最均衡的选择。
- **需要保留轮廓和骨架**:选择最远点采样(FPS),但需注意其计算成本。
- **需要保留几何细节**:选择法向量空间采样(NSS)。
- **与特定任务(如分类)结合**:深度学习降采样是未来的趋势,能带来显著的性能提升。
理解这些方法的内在原理、优缺点和适用场景,是高效处理和分析三维点云数据的关键第一步。
---
**参考资料:**
> 1. 点云 | 降采样专题 - 墨天轮 (modb.pro)
> 2. 三维点云处理:5滤波:降采样 - CSDN博客
> 3. 祝瑞红. 基于三维点云的工件检测与姿态估计研究.
> 4. 知乎:点云降采样——Mver
- 1本网站名称:MuQYY
- 2本站永久网址:www.muqyy.top
- 3本网站的文章部分内容可能来源于网络,仅供大家学习与参考,如有侵权,请联系站长 微信:bwj-1215 进行删除处理。
- 4本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
- 5本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
- 6本站资源大多存储在云盘,如发现链接失效,请联系我们我们会在第一时间更新。



暂无评论内容